Написати нам


Все про AI Max у Google Ads: Як працює штучний інтелект від Google для оптимізації пошукових кампаній, що варто врахувати перед запуском AI Max та яких результатів очікувати.

Promodo увійшла до шортліста European Search Awards 2026 з чотирма кейсами разом із клієнтами INTERTOP та Exist. Це вже другий рік поспіль, коли агенція виходить у фінал престижної європейської премії.

Як рекламувати інтернет-магазин через SEO, контекстну рекламу, email-маркетинг та медіа. Комплексний підхід для реклами інтернет-магазину допоможе як розкрутити онлайн бізнес та швидко збільшити трафік і продажі.

.png)


Друге півріччя 2025
Що відбувалося з українським eCommerce у другому півріччі 2025? Аналізуємо доходи, трафік, середній чек і канали залучення — ключові висновки та тенденції ринку.

Хто очолює рейтинг брендів в Україні? Ми зібрали лідерів різних ніш за кількістю пошукових запитів — дізнайтеся, хто №1 у 2025 році.

Досліджуємо, як зростає попит на подарунки до Дня матері. Коли починати рекламні кампанії, що купують українці та як бізнесу підготуватися до травневого піку.

Майже 3 млн запитів на паску та зростання панеттоне: аналіз Google Trends, поведінки користувачів і поради для планування продажів.

Аналіз пошукових запитів про подарунки на 8 березня: що можна подарувати на Міжнародний жіночий день, які ідеї подарунку на 8 березня шукають українці та що дарують жінкам, дівчатам, мамам, колегам та подругам найчастіше.

Promodo проаналізувала пошукові запити «як готувати кутю», щоб з’ясувати, як українці перейшли на святкування Різдва 25 грудня. Коротке міні-дослідження з даними.

Як масштабувати маркетинг 2000+ аптек: команда, клієнтський досвід, TikTok, AI та поведінка покупців — інтерв’ю з CMO «Подорожник»

Керівниця центру маркетингових комунікацій МХП Анастасія Ливинець розповідає про роботу команди з 47 фахівців, інхаус-креатив, роботу з інфлюенсерами та критерії відбору лідів.

Дізнайтеся, як працює найбільша програма лояльності України, навіщо збирати бали роками та чому обличчя менеджерів у рекламі працюють краще за креативи.

У новому епізоді подкасту Додана цінність поговорили з Дариною Скалун — маркетинг-директоркою найбільшого в Україні магазину іграшок «Будинок Іграшок».

Як використовувати SPCL-фреймворк від Алекса Гормозі (Alex Hormozi). Основні тригери впливу (Status, Power, Credibility, Likeness) для створення контенту, який впливає, залучає та продає.

Як працює просування мобільного додатку. ТОП ефективних способів просування мобільних застосунків та масштабування. Помилки, яких варто уникати. Успішні кейси mobile apps promotion від Promodo.

Гайд із Social Media Optimization: як працює SMO, як оптимізувати профіль і контент, щоб потрапляти в пошук соцмереж і Google.

Які формати реклами існують у Meta? Розбираємо типи товарних оголошень: зображення, відео, карусель і підбірки товарів.
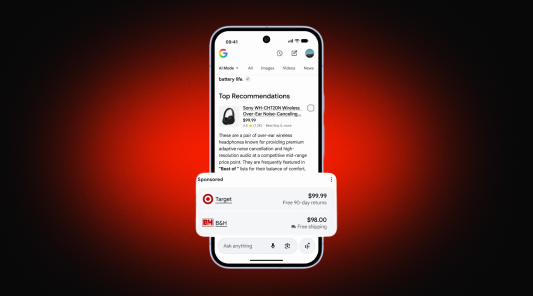
Революція в Google Search: реклама всередині відповідей ШІ та купівля товарів без переходу на сайт. Розбираємо деталі запусків у США та перспективи для України.




















.png)